

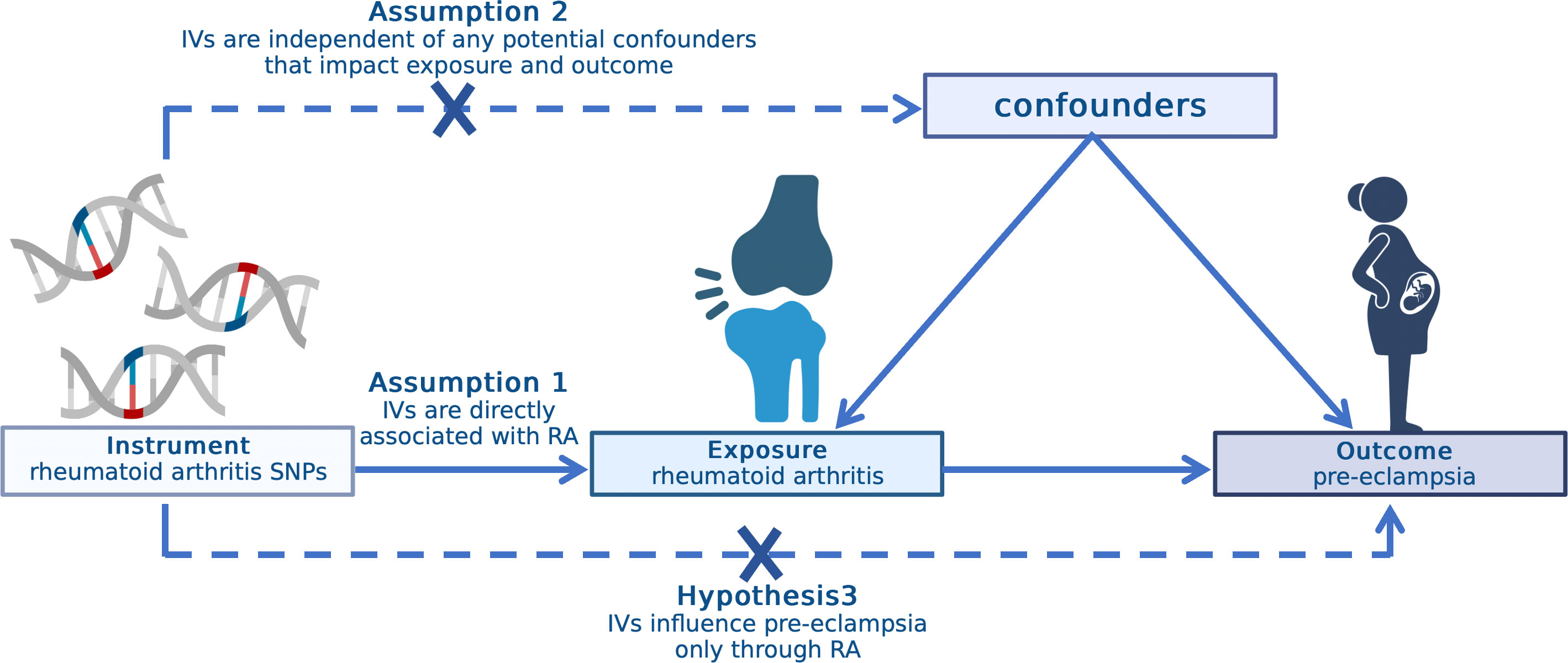
Introduction: The Genetic Courtroom of Causality
Imagine a courtroom where genes serve as impartial judges. They were assigned long before our birth, unaffected by our choices or environments. In this courtroom, Mendelian Randomization (MR) acts as the trial process—determining whether a suspect (like cholesterol or sleep duration) is truly guilty of causing a disease (like heart attack or diabetes), or merely an innocent bystander.
In an era where correlations are often mistaken for causation, MR offers a revolutionary way to uncover the truth. Just as a detective looks for clues that cannot lie, data scientists and biostatisticians look to our genes for unbiased evidence. For anyone mastering a data scientist course in Pune, understanding MR is like learning to separate noise from signal—a core skill in causal inference.
1. The Genetic Lottery: Nature’s Built-In Randomized Trial
Every human inherits a unique combination of genes, like tickets drawn in a massive biological lottery. This random assortment—first observed by Gregor Mendel—forms the foundation of Mendelian Randomization. Because these genetic variants are randomly assigned at conception, they mimic the conditions of a randomized controlled trial (RCT).
Consider the FTO gene, often linked to body mass index (BMI). People with certain FTO variants tend to have higher BMI, independent of lifestyle or environment. By examining how these genetic differences correlate with health outcomes, researchers can infer causality. If higher BMI caused by genetic variation increases diabetes risk, then obesity itself—rather than diet or stress alone—is a causal factor.
This method is particularly powerful for data-driven professionals pursuing a data science course who want to understand how to design experiments in non-experimental settings. MR gives them the blueprint: leverage natural randomness to uncover hidden cause-and-effect relationships.
2. Case Study 1: Cholesterol, Genes, and Heart Health
For decades, scientists debated whether lowering cholesterol actually prevents heart disease or if both were merely correlated. Enter Mendelian Randomization. Researchers identified genetic variants in the HMGCR gene—responsible for cholesterol regulation—and found that people carrying cholesterol-lowering variants had a significantly lower risk of coronary heart disease.
This genetic evidence mirrored the effect of statin drugs, which inhibit the same gene pathway. The verdict was clear: lowering LDL cholesterol does indeed cause a reduction in heart attack risk. MR didn’t just confirm what clinical trials later supported—it predicted it.
For students in a data scientist course in Pune, this case underscores the beauty of causal inference: sometimes, the answers to medical mysteries lie not in hospital records but deep in our DNA, waiting for the right algorithm—or analytical mindset—to uncover them.
3. Case Study 2: Alcohol Consumption and Stroke Risk
Correlation once deceived scientists into believing that moderate drinking protected the heart. Observational studies showed that moderate drinkers had fewer strokes and heart issues compared to non-drinkers. But MR flipped this narrative.
Using genetic variants in the ALDH2 gene, which affects alcohol metabolism, researchers divided populations based on their genetic ability to tolerate alcohol. Those with a gene variant causing alcohol flushing (and therefore consuming less alcohol) had lower blood pressure and stroke risk. The supposed “protective effect” of moderate drinking vanished.
Through this study, Mendelian Randomization demonstrated its power to expose the illusions created by lifestyle correlations. For anyone immersed in a data science course, this is a masterclass in critical thinking—how bias and confounding can distort reality unless one leverages rigorous causal frameworks.
4. Case Study 3: Vitamin D and COVID-19 Severity
At the height of the pandemic, social media brimmed with claims that Vitamin D supplementation could prevent severe COVID-19 outcomes. Observational studies seemed to support it: patients with higher Vitamin D levels fared better. Yet, were these effects causal—or were healthier individuals simply more likely to have higher Vitamin D?
Mendelian Randomization provided clarity. Genetic variants associated with lifelong higher Vitamin D levels were analyzed across thousands of genomes. The results were striking: genetically predicted Vitamin D levels showed no significant causal effect on COVID-19 severity. The myth unraveled.
Here, MR served as a data-driven compass, guiding global health decisions amid uncertainty. For modern analysts enrolled in a data scientist course in Pune, this example is a reminder that even in crises, rigorous causal reasoning must trump convenience and correlation.
5. Beyond Biology: The Broader Lesson for Data Scientists
While MR originated in genetics, its principles transcend biology. The same logic—using instrumental variables to infer causality—applies to economics, public policy, and digital analytics. Whether estimating the impact of education on income or ad exposure on sales, the goal remains the same: isolate true cause from coincidental correlation.
Students in a data science course who master this mindset gain an extraordinary edge. They learn not just to build predictive models, but to question why something happens. MR embodies this transition—from mere pattern recognition to genuine understanding.
Conclusion: The Gene Whisperers of Causality
Mendelian Randomization teaches us that truth often hides behind randomness. By letting genes act as nature’s randomizers, scientists have redefined how we establish cause and effect in complex systems. It’s more than a statistical tool—it’s a philosophy of curiosity, discipline, and humility.
For aspiring data professionals, especially those exploring a data scientist course in Pune, MR stands as a metaphor for their own journey: the quest to find order in chaos, to separate truth from noise, and to let evidence—not assumption—guide their reasoning.
In the end, Mendelian Randomization reminds us that nature, like data, never lies—it only waits for the right question to reveal its truth.
Business Name: ExcelR – Data Science, Data Analytics Course Training in Pune
Address: 101 A ,1st Floor, Siddh Icon, Baner Rd, opposite Lane To Royal Enfield Showroom, beside Asian Box Restaurant, Baner, Pune, Maharashtra 411045
Phone Number: 098809 13504
Email Id: enquiry@excelr.com